Why Consumer AI Success Does Not Easily Translate to the Enterprise
For quite some time, I have been thinking about writing a post with a classic consultant-style 2×2 matrix. So, here it is.
There has been no shortage of discussion around why AI has struggled to deliver broad success in the enterprise. At this point, opinions are everywhere, and many “experts” are quick to offer conclusions. What is less common, however, is a deeper look at the structural reasons behind the challenge. Interestingly, this same question often comes up in the classes I teach as well.
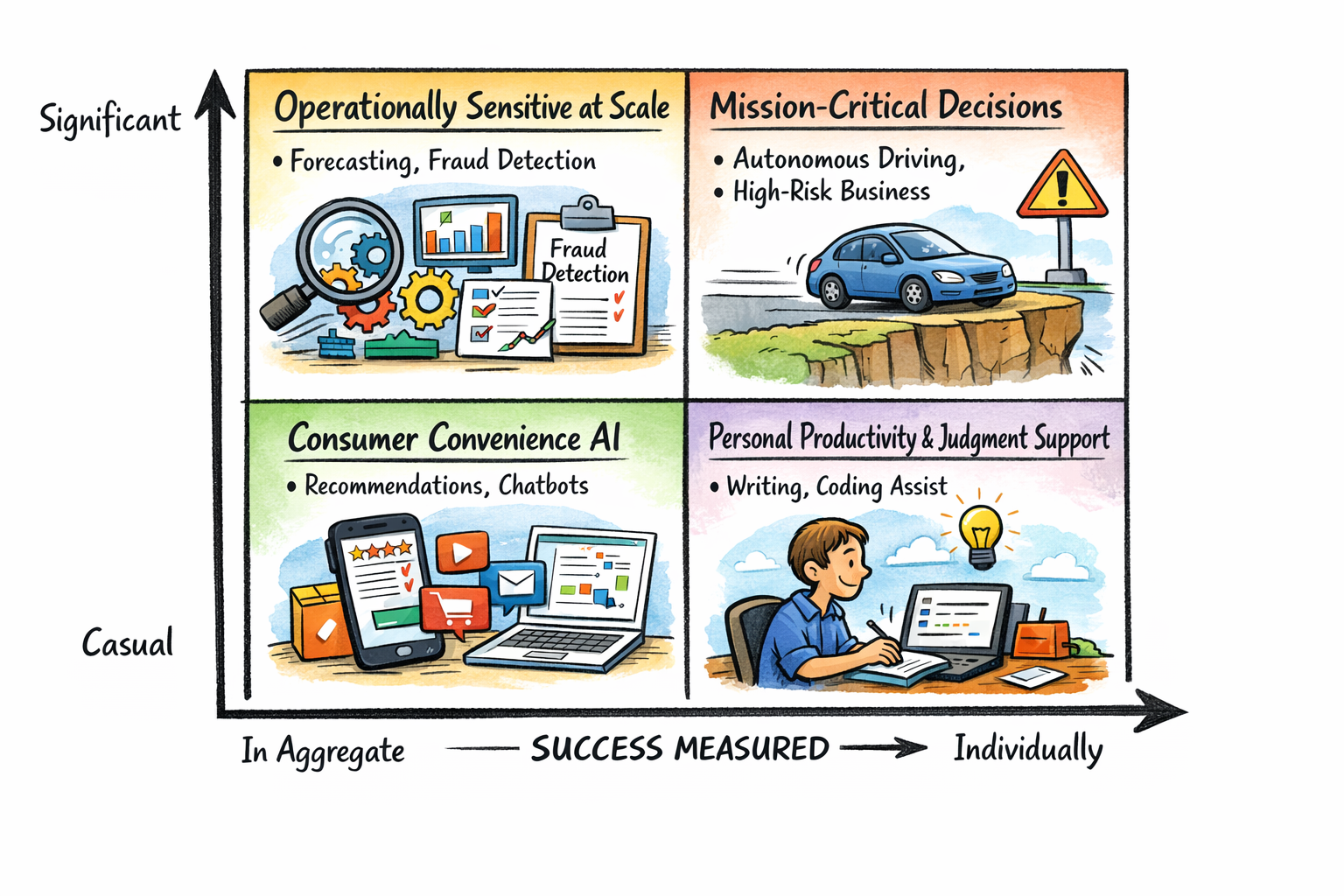
One simple way to frame the issue is through a 2×2 matrix.
On the y-axis, we can map the level of consequence, ranging from casual to significant. Casual means the outcome of a mistake is relatively minor. It may create inconvenience, frustration, or a poor user experience, but it is unlikely to cause major harm. Significant, on the other hand, refers to situations where a wrong decision can lead to serious damage, whether financial, operational, legal, or even physical.
On the x-axis, we can think about how success is measured. In some cases, success is evaluated in aggregate, meaning the system is judged by its average performance across many users or many interactions. In other cases, success is judged at the individual level, where each output or decision must stand on its own.
Once we look at AI through this lens, the landscape becomes much clearer.
The lower-left quadrant is what I would call consumer convenience AI. These are low-consequence applications where success is judged in aggregate. Recommendation engines, ad targeting, content ranking, and basic chatbot summarization all fit here. If the recommendation is not very good, the user may be mildly annoyed, but the consequence is limited. Likewise, if a chatbot produces a mediocre summary, the damage is usually small. In these settings, a small percentage of poor outcomes is entirely acceptable because the impact of any single error is low. As long as the system performs well overall, it is considered a success.
The lower-right quadrant is personal productivity or judgment support. These applications are still relatively low consequence, but success is experienced one user or one task at a time. Examples include drafting an email, helping write code, organizing thoughts, or supporting brainstorming. A mistake here may be frustrating and may reduce trust in the tool, but it usually does not create material damage. What makes this quadrant different from the lower-left is that the user evaluates the result much more individually than statistically. The experience is personal. If the output is poor for that one task, the user feels the failure directly, even if the overall system metrics look strong.
The upper-left quadrant is operationally sensitive at scale. These are higher-impact domains where errors matter, sometimes quite a bit, but success can still be measured at a broader portfolio or system level. Examples include fraud detection, demand forecasting, preventive maintenance, and large-scale customer service triage. In these scenarios, mistakes are costly, but organizations may still tolerate some level of imperfection if the system materially improves the overall outcome. A forecasting model does not need to be perfect in every instance to generate real business value. A fraud system may produce some false positives or miss some cases, yet still be worthwhile if it meaningfully reduces losses. This is an important quadrant because many enterprise AI use cases actually sit here, not at the far extreme.
Then we arrive at the upper-right quadrant: mission-critical decisions. This is the hardest quadrant, and in many ways it captures the core challenge of enterprise AI. These are high-consequence use cases where each decision must be right on its own merits. Autonomous driving is the clearest example. If a self-driving car makes a mistake, the outcome can be severe, even life-threatening. In that context, it is not acceptable to say the system works well most of the time. A 95% success rate is not nearly enough. In some situations, even one failure is too many.
This upper-right quadrant is also where the most demanding enterprise use cases live. In business, this may include decisions tied to safety, compliance, major financial commitments, production planning, or other workflows where one serious mistake can be unacceptable. That is why enterprise AI is often much closer to autonomous driving than to consumer recommendation systems.
This distinction matters because much of the public excitement around AI has been driven by applications in the lower-left and lower-right quadrants, where the cost of failure is manageable and users are more forgiving. Those successes created the impression that AI could be rolled easily into every part of the enterprise. But that assumption misses how different the requirements become as we move upward in consequence and rightward toward decision-by-decision accountability.
That, in my view, is one of the biggest reasons enterprise AI adoption has been harder than many people expected. The issue is not simply that the technology is immature, although that can certainly be part of it. The deeper challenge is that enterprise use cases often operate in quadrants where the stakes are higher and the standard for success is far less forgiving.
A lot of AI works well when the cost of being wrong is low and performance can be averaged across millions of interactions. Enterprise AI becomes much harder when the cost of being wrong is high, and when people care deeply about the one decision in front of them rather than the average across the system.
That is the real challenge. And it is also why building AI for mission-critical enterprise use cases requires a very different mindset from building casual consumer tools.





